データ指向アプリケーションデザインを読んだ。
今年2冊目はデータ指向アプリケーションデザインを読んだ。

全部自分の中で咀嚼してブログに書くには2週目が必要そうだったので読書メモは一部だけ。
また気が向いたときに読んで更新します。 一周してどこにどういうことが書いてあるかは把握したけど理解まではしてない感じ。
ここでいう「データ指向」とは、
CPUのサイクルがボトルネックとなる演算指向のアプリケーションに対して、データの量や複雑さ、変化の速度が主な課題であるアプリケーションのこと
である。 具体的には、最近のマイクロサービスのような水平スケーリングするアプリケーションが思い浮かぶ。
この本は3部構成で
- データ指向アプリケーションの設計を支える基本的な概念
- 分散配置されたデータに対するアプローチについて
- データベース、キャッシュなど異種混合なデータ保存場所からデータを取り出すシステムについて
のようになっている。そしてだいぶ分量があった。
この本によって著者が期待することは、読者が
ある目的のためにはどういった種類の技術を用いるのが適切なのかを的確に判断し、優れたアプリケーションのアーキテクチャの基盤を構築するためのツール群の組み合わせ方を理解
できるようになることである。
第Ⅰ部 データシステムの基礎
1章 信頼性、スケーラビリティー、メンテナンス性に優れたアプリケーション
信頼性
フォールトは障害と同じではないことに注意してください[2]。通常フォールトは仕様を満たしていないコンポーネントとして定義されますが、障害はシステムが全体として必要なサービスのユーザーへの提供を止めてしまった場合を指します。
なるほど。曖昧だったのでこう書かれるとわかりやすい。
大まかに言って信頼性とは「何か問題が生じたとしても正しく動作し続けること」と言えるでしょう。
とあり、「フォールトが生じたとしても正しく動作し続けること」とも言い換えられそうだ。 耐障害性の考え方は考えうるすべてのフォールト(地球がブラックホールに飲み込まれるとか)に耐えるといったものではなく、ある種のフォールトに対する体制について議論するだけとも書いてあった。
耐障害性のテストの例としてはNetflixのChaos Monkeyが紹介されていた。
フォールトの例として、
- ハードウェアの障害。対策としてローリングアップグレードができる仕組み
- ソフトウェアのエラー。対策として徹底したテストや監視とアラートなど
- ヒューマンエラー。対策としてユニットテストやモニタリング、サンドボックス、トレーニングなど複数のアプローチを組み合わせる
があげられている。
最大限に努力しても、人間には信頼性がないことが知られています。
が印象的だった。同意。
スケーラビリティー
負荷の増大に対してシステムが対応できる能力のことを指して使われる言葉。 毎秒のリクエスト数やキャッシュのヒット率など負荷のパラメータによってスケーラビリティを実現するための適切なアプローチが異なる。
負荷のパラメータが増加した際に重要なのは、レスポンスタイムやバッチ処理のスループットなどのシステムのパフォーマンスだ。
パフォーマンスを見る例としてレスポンスタイムでは、平均よりもパーセンタイルを使うことがおすすめされていた。 つまり、分布を見るということだな。 ちょっと直感的に理解するためにRで図を描いてみた。
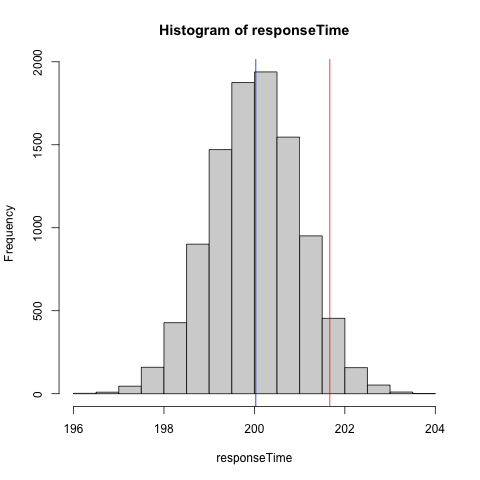 図1. レスポンスタイムのヒストグラム(イメージ)
図1. レスポンスタイムのヒストグラム(イメージ)
これは適当な平均200msでレスポンスされるリクエストのヒストグラムだ。x軸がレスポンスタイム、y軸が頻度を表している。 レスポンスタイムの中央値(青)が200msだったらリクエストの半分に対して200ms以下でレスポンスされたことを意味する。
中央値は50パーセンタイル値とも呼ばれる。また、はずれ値がどれほど悪いかを知るには95,99,99.9パーセンタイル値を見ることが紹介されていた。 これらはn%のリクエストがそれ以上に高速だったことを示す。
図1では95パーセンタイル値を赤い線で表した。この図のようにはずれ値がない安定したレスポンスタイムの場合は平均値や中央値と95パーセンタイル値の差が少ないが、はずれ値が存在する場合この95パーセンタイル値が大きい値をもつことになる。 このような大きなパーセンタイルのレスポンス値はテイルレイテンシと呼ばれ、ユーザーのサービス体験に直接的に関係しており、 サービスレベル目標(SLO)やサービスレベルアグリーメント(SLA)に以下のようにしばしば利用される。
SLAはサービスのレスポンスの中央値が200ミリ秒以下であり、99パーセンタイル値が1秒以下であればサービスは動作中であり(レスポンスタイムがこの規定よりも長ければ、それはダウンしているものと見なせる)、サービスは最低でも99.9%の時間にわたって動作していなければならない。
負荷への対処には、垂直スケーリング(マシンを強力なものにする)と水平スケーリング(複数の比較的小さいマシンに負荷を分散させる)があり、 それらを負荷に応じて自動的に行うエラスティックなシステムもある。
ヒストグラムを描くのに書いたRスクリプトもメモしておく。
responseTime <- rnorm(10000, mean = 200)
responseTime <- responseTime[responseTime >= 0] # 負値は省く
qts <- quantile(responseTime, probs = c(.0, .95))
png("responseTime.png")
hist(responseTime)
abline(v = median(responseTime), col = "blue")
abline(v = qts[2], col = "red")
dev.off()
メンテナンス性
ソフトウェアシステムに関わる多くの人々は、いわゆるレガシーシステムのメンテナンスを嫌います。
わかる。好きな人いるんだろうか?
運用性、単純性、進化性(拡張性、修正の容易性、プラスティシティ)の3つの設計原理に特に注意をしてメンテナンスの際の苦痛を最小化しようということが書いてあった。
メンテナンスの際の苦痛を最小化し、レガシーとなるソフトウェアを私たち自身が生み出してしまうのを避けるやり方でソフトウェアを設計することは可能であり、そうするべきです。そのためには、ソフトウェアシステムのための3つの設計原理に特に注意を払いましょう。
もし何か質問やフィードバックがありましたら、 @biosugar0 までお願いします。
2021-02-28